9月8日,B站(Bilibili)宣布正式开源其自研语音生成大模型IndexTTS-2.0。这是首个支持精确时长控制的自回归零样本文本转语音系统。
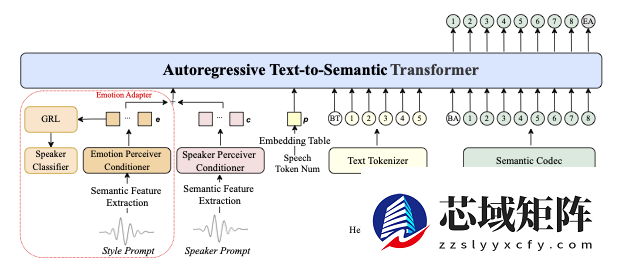
相比较传统逐token生成的TTS系统,IndexTTS-2.0首次在自回归架构中实现了精准时长控制,特别适合视频配音等需严格音画同步的应用场景。

IndexTTS-2.0支持两种生成模式,并在声音表达上实现了情感特征与说话人音色的解耦。这意味着用户可以独立指定音色来源和情绪来源。例如,可以用一段音频保留音色,再用另一段不同情感的音频或文本描述赋予情绪。在零样本条件下,模型能精准还原目标音色并完全重现指定情绪。

为提升高情感表达下的语音清晰度,团队引入了GPT潜在表示,并设计三阶段训练策略增强生成稳定性。基于Qwen3微调实现的“软指令”机制,允许用户通过自然语言描述来直观控制情绪方向,降低使用门槛。
多数据集实验表明,IndexTTS-2.0在词错率、说话人相似度和情绪保真度上均超越当前最先进零样本TTS模型。该方法具备良好的扩展性,可应用于其他大型自回归TTS系统。团队将公开代码和预训练权重,推动学术研究与产业落地。


























